第一节:内容规则
回顾一下第 2 章第 4 节 What(内容),页面和元素的事件采集都有内容相对应,下面通过一些具体例子来解释元素内容的具体规则。
- 例子一

最简单的例子如上图的「免费试用」按钮,A 标签是叶子结点,内容即是标签文本,即“免费试用”。
2.例子二

例子二是一张图片,IMG 标签也是叶子结点,内容是 alt 文本,即“提高注册转化,降低获客成本”。
3.例子三
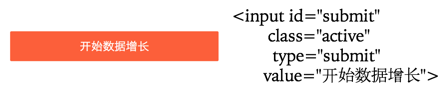
例子三是一个提交按钮,INPUT 标签也是叶子结点,内容是 value 属性,即“开始数据增长”。
4.例子四

例子四不再是一个叶子结点,而是一个简单按钮容器,内容是其内文本,即“新建”。
5.例子五

例子五也是一个容器结点,因为 A 结点是空内容,同时 LI 结点是倒数第二层结点,所以会采集 LI 结点。原本 LI 结点的内容为空,但是因为设置了 title 属性,所以采集到的内容是 title 属性值,即“上一页”。
6.例子六

例子六和例子五一样,除了用 data-growing-title 属性替代了 title 属性。如果你不希望用户悬浮在结点上后出现鼠标锚点出现文本,可以用 data-growing-title 来替代 title。
7.例子七

例子七的容器被采集的会有多个元素,比如叶子结点 IMG 标签、H2 标签,内容逻辑如例子一和例子二。作为倒数第二层结点,P 标签也会被采集,其内容是内文本内容,即“分析广告投放渠道 转化率监控 用更低成本获取客户”。
8.例子八

例子八跟例子七是同一个容器,在例子七中已经介绍过 IMG 标签、H2 标签和 P 标签都会采集。在例子八特别指出的是 A 标签,A 标签和 BUTTON 标签一样,不管层次都会采集,这里 A 标签没有指定 title 属性,所以内容默认会使用 href 属性,即“/conversion"。
还有一些额外的规则,具体可以看第 2 章第 4 节内容规则流程图。
应用案例
当我们知道不同的 DOM 结构采集的内容的不同逻辑,那么内容可以拿来做什么实际用途呢?
在上一章定义元素这一节中,我们介绍了内容可以用来做匹配的规则条件,比如对于例子一,内容可以用来严格匹配“免费试用”按钮。这是非常常用的应用场景。
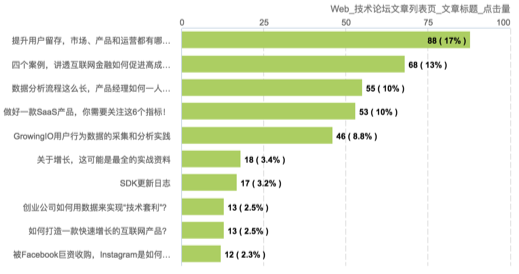
另外一个常用场景是把内容作为维度,查看不同内容的数据,比如对于博客列表页,如下图。
当我们圈选列表里的文章标题时,我们可以使用圈选选项里的“同类元素”忽略内容和位置,定义为标签“Web_技术论坛文章列表页_文章标题”。之后,使用「元素内容」作为维度,我们就能很简单的得到不同文章标题的曝光量、点击量和点击率,了解在某一个时间段文章的热度。